Q: What is a data pipeline?Answer: A series of steps in which data is processed.
Example:
Automated marketing emails
Real-time pricing in rideshare apps
Targeted advertising based on browsing history
Remarks: It's typically using either ETL or ELT.
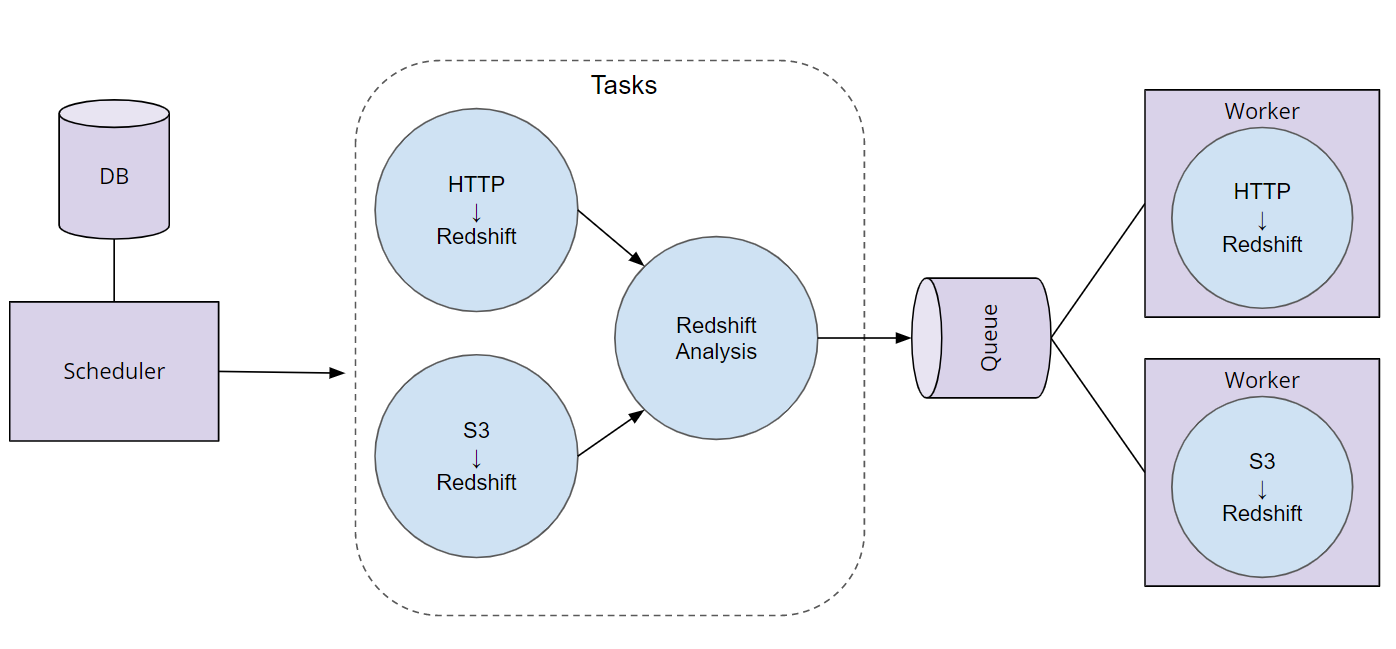
Q: Given an example of a data pipeline to accomplish the following: a bikeshare company wants to efficiently improve availability of bikes.Answer:
Load application event data from a source such as S3 or Kafka
Load the data into an analytic warehouse such as RedShift.
Perform data transformations that identify high-traffic bike docks so the business can determine where to build additional locations.
Q: Describe the difference between ETL and ELT.Answer:
ETL is normally a continuous, ongoing process with a well-defined
workflow. ETL first extracts data from homogeneous or heterogeneous data
sources. Then, data is cleansed, enriched, transformed, and stored
either back in the lake or in a data warehouse.
ELT (Extract, Load, Transform) is a variant of ETL wherein the
extracted data is first loaded into the target system. Transformations
are performed after the data is loaded into the data warehouse.
Remarks: ELT typically works well when the target system is powerful enough to handle transformations. Analytical databases like Amazon Redshift and Google BigQ.
Q: What is S3?Answer:
Amazon S3 has a simple web services interface that you can use to
store and retrieve any amount of data, at any time, from anywhere on the
web.
It gives any developer access to the same highly scalable,
reliable, fast, inexpensive data storage infrastructure that Amazon uses
to run its own global network of web sites.
Apache Kafka is an open-source stream-processing software platform developed by Linkedin and donated to the Apache Software Foundation, written in Scala and Java.
The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Remarks:
Its storage layer is essentially a massively scalable pub/sub message queue designed as a distributed transaction log, making it highly valuable for enterprise infrastructures to process streaming data."
Q: What is RedShift?Answer: Amazon Redshift is a fully managed, petabyte-scale data warehouse
service in the cloud.
Remarks:
The first step to create a data warehouse is to launch a set of nodes, called an Amazon Redshift cluster.
After you provision your cluster, you can upload your data set and then perform data analysis queries.
Regardless of the size of the data set, Amazon Redshift offers fast query performance using the same SQL-based tools and business intelligence applications that you use today.
Q: What is data validation?Answer: It is the process of ensuring that data is present, correct
& meaningful.
Remarks: Ensuring the quality of your data through automated validation checks is a critical step in building data pipelines at any organization.
Q: List some data validation steps for the bikeshare example.Answer: After loading from S3 to Redshift:
Validate the number of rows in Redshift match the number of records in S3
Once location business analysis is complete:
Validate that all locations have a daily visit average greater than 0
Validate that the number of locations in our output table match the number of tables in the input table.
Q: Are there real world cases where a data pipeline is not a DAG?Answer:
It is possible to model a data pipeline that is not a DAG, meaning that
it contains a cycle within the process.
However, the vast majority of
use cases for data pipelines can be described as a directed acyclic
graph (DAG).
This makes the code more understandable and maintainable.
Q: Can we have two different pipelines for the same data and can we merge them back together?Answer: Yes. It's not uncommon for a data pipeline to take the same dataset, perform two different processes to analyze it, then merge the results of those two processes back together.
Q: How could the bikeshare example be modeled as a DAG?Answer:
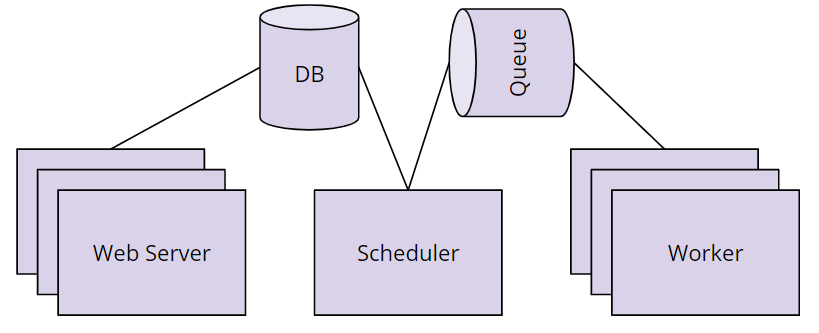
Q: What are the five components of airflow?Answer:
The scheduler orchestrates the execution of jobs on a
trigger or schedule. It chooses how to prioritize the running
and execution of tasks within the system.
The work queue is used by the scheduler in most Airflow installations to deliver tasks that need to be run to the workers.
Worker processes execute the operations defined in each DAG. In most Airflow installations, workers pull from the work queue
when it is ready to process a task. When the worker completes the
execution of the task, it will attempt to process more work from the work queue until there is no further work remaining.
Database saves credentials, connections, history, and configuration. The database, often referred to as the metadata database, also stores the state of all tasks in the system.
The web Interface provides a control dashboard for
users and maintainers. Throughout this course you will see how the web
interface allows users to perform tasks such as stopping and starting
DAGs, retrying failed tasks, configuring credentials,
Example:
Q: Describe the order of operations for an Airflow DAG.Answer:
The scheduler starts DAGs based on time or external triggers.
Once a DAG is started, the scheduler looks at the steps within the
DAG and determines which steps can run by looking at their dependencies.
The scheduler places runnable steps in the queue.
Workers pick up those tasks and run them.
Once the worker has finished running the step, the final status of
the task is recorded and additional tasks are placed by the scheduler
until all tasks are complete.
Once all tasks have been completed, the DAG is complete.
Example:
Q: What does the airflow scheduler do?Answer: It starts DAGs based on triggers or schedules and moves them towards completion.
Q: What do the Airflow workers do?Answer: They run and record the outcome of individual pipeline tasks.
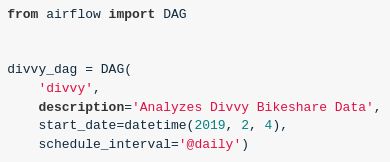
Q: How to create a DAG in Airflow?Answer: Creating a DAG is easy.
Give it a name,
a description,
a start date, and an
interval.
Example:
Q: What are operators in Airflow?Answer: They define the atomic steps of work that make up a DAG.
Example: Remarks: Instantiated operators are referred to as Tasks.
Q: What does Airflow do when the start date is in the past?Answer: Airflow will run your DAG as many times as there are schedule intervals between that start date and the current date.
Q: What are the nodes and edges in an Airflow DAG?Answer:
Nodes = Tasks
Edges = Ordering and dependencies between tasks
Remarks:
Task dependencies can be described programmatically in Airflow using >> and <<
a >> b means a comes before b
a << b means a comes after b
Q: How to programmatically describe task dependencies in Airflow?Answer:
Task dependencies can be described programmatically in Airflow using >> and <<
Use `>>` to denote that `goodbye_world_task` depends on `hello_world_task` ```hello_world_task >> goodbye_world_task```
Q: What are Airflow Hooks?Answer: Hooks provide a reusable interface to external systems and databases.
Example: Remarks: With hooks, you don’t have to worry about how and where to store these connection strings and secrets in your code.
Q: What's the purpose of runtime variables in Airflow?Answer: They allow users to “fill in the blank” with important runtime variables for tasks.
Example: Remarks: Here is the Apache Airflow documentation on context variables that can be included as kwargs.
Q: What is a Task in Airflow?Answer: An instantiated step in a pipeline fully parameterized for execution.
Q: What is data lineage?Answer: The data lineage of a dataset describes the discrete steps involved in the creation, movement, and calculation of that dataset.
Q: Why is data lineage important?Answer:
Instilling Confidence: Being able to describe the
data lineage of a particular dataset or analysis will build confidence
in data consumers (engineers, analysts, data scientists, etc.) that our
data pipeline is creating meaningful results using the correct datasets.
Defining Metrics: Another major benefit of
surfacing data lineage is that it allows everyone in the organization to
agree on the definition of how a particular metric is calculated.
Debugging: Data lineage helps data engineers track
down the root of errors when they occur. If each step of the data
movement and transformation process is well described, it's easy to find
problems when they occur.
Remarks:
In general, data lineage has important implications for a business.
Each
department or business unit's success is tied to data and to the flow
of data between departments.
For e.g., sales departments rely on data to
make sales forecasts, while at the same time the finance department
would need to track sales and revenue.
Each of these departments and
roles depend on data, and knowing where to find the data.
Data flow and
data lineage tools enable data engineers and architects to track the
flow of this large web of data.
Q: Why use schedules in airflow?Answer:
Pipeline schedules can reduce the amount of data that needs to be processed in a given run. It helps scope the job to only run the data for the time period since the data pipeline last ran.
Using schedules to select only data relevant to the time period of the given pipeline execution can help improve the quality and accuracy of the analyses performed by our pipeline.
Running pipelines on a schedule will decrease the time it takes the pipeline to run.
An analysis of larger scope can leverage already-completed work. For example, if the aggregates for all months prior to now have already been done by a scheduled job, then we only need to perform the aggregation for the current month and add it to the existing totals.
Q: Which factors should be considered in selecting a time period for scheduling?Answer:
What is the size of data, on average, for a time period? If an entire years worth of data is only a few kb or mb, then perhaps its fine to load the entire dataset. If an hours worth of data is hundreds of mb or even in the gbs then likely you will need to schedule your pipeline more frequently.
How frequently is data arriving, and how often does the analysis need to be performed? If our bikeshare company needs trip data every hour, that will be a driving factor in determining the schedule. Alternatively, if we have to load hundreds of thousands of tiny records, even if they don't add up to much in terms of mb or gb, the file access alone will slow down our analysis and we’ll likely want to run it more often.
What's the frequency on related datasets? A good rule of thumb is that the frequency of a pipeline’s schedule should be determined by the dataset in our pipeline which requires the most frequent analysis. This isn’t universally the case, but it's a good starting assumption. For example, if our trips data is updating every hour, but our bikeshare station table only updates once a quarter, we’ll probably want to run our trip analysis every hour, and not once a quarter.
Q: What is the scope of a data pipeline?Answer: It is the time delta between the current execution time and the end time of the last execution.
Q: What is data partitioning?Answer: It is the process of isolating data to be analyzed by one or more attributes, such as time, logical type, or data size.
Remarks: It often leads to faster and more reliable pipelines.
Q: Why should you use data partitioning?Answer:
Pipelines designed to work with partitioned data fail more
gracefully.
Smaller datasets, smaller time periods, and related concepts
are easier to debug than big datasets, large time periods, and
unrelated concepts.
Partitioning makes rerunning failed
tasks much simpler. It also enables easier redos of work, reducing cost
and time.
Remarks:
Another great thing about Airflow is that if your data is partitioned appropriately, your tasks will naturally have fewer dependencies on each other.
Because of this, Airflow will be able to parallelize execution of your DAGs to produce your results even faster.
Q: What are four common types of data partitioning?Answer:
Location
Logical
Size
Time
Q: What is logical partitioning?Answer: The process of breaking conceptually related data into discrete groups for processing.
Q: What is time partitioning?Answer: It is the process of processing data based on a schedule or when it was created.
Q: What is size partitioning?Answer: It is the process of separating data for processing based on desired or required storage limits.
Q: How would you set a requirement for ensuring that data arrives within a certain timeframe of a DAG starting?Answer: Using a service level agreement (SLA).
Q: What are the most common types of user-created plugins?Answer: Operators and Hooks.
Q: How to create a custom operator?Answer:
Identify Operators that perform similar functions and can be consolidated
Define a new Operator in the plugins folder
Replace the original Operators with your new custom one, re-parameterize, and instantiate them.
Q: What is Airflow contrib and why is it useful?Answer:
It contains Operators and hooks for common data tools like Apache Spark and
Cassandra, as well as vendor specific integrations for Amazon Web
Services, Azure, and Google Cloud Platform can be found in Airflow
contrib.
Therefore you should always check it before building your own airflow plugins to see if what you need already exists.
Remarks: If the functionality exists and its not quite what you want, that’s a great opportunity to add that functionality through an open source contribution.
Q: Which three rules should you follow when designing DAGs?Answer:
DAG tasks should be designed such that they:
are Atomic and have a single purpose
Maximize parallelism
Make failure states obvious
Remarks:
Every task in your dag should perform only one job.
“Write programs that do one thing and do it well.” - Ken Thompson’s Unix Philosophy
Q: What are the benefits of task boundaries?Answer:
Re-visitable: Task boundaries are useful for you if you revisit a
pipeline you wrote after a 6 month absence. You'll have a much easier
time understanding how it works and the lineage of the data if the
boundaries between tasks are clear and well defined. This is true in the
code itself, and within the Airflow UI.
Tasks that do just one thing are often more easily parallelized.
This parallelization can offer a significant speedup in the execution of
our DAGs.
Q: What are benefits of SubDAGs?Answer:
Decrease the amount of code we need to write and maintain to create a new DAG
Easier to understand the high level goals of a DAG
Bug fixes, speedups, and other enhancements can be made more quickly and distributed to all DAGs that use that SubDAG
Q: What are drawbacks of using SubDAGs?Answer:
Limit the visibility within the Airflow UI
Abstraction makes understanding what the DAG is doing more difficult
Encourages premature optimization
Q: Which pipeline monitoring options does airflow provide?Answer:
SLAs
Emails and alerts
Metrics
Q: What's the purpose of SLAs in airflow?Answer:
SLAs define the time by which a DAG must complete.
For time-sensitive applications they are critical for
developing trust amongst your pipeline customers and ensuring that data
is delivered while it is still meaningful.
Slipping SLAs can also be early indicators of performance problems, or a need to scale up the size of your Airflow cluster
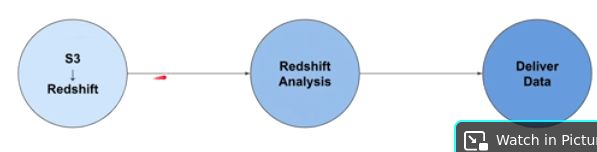
 Remarks: Instantiated operators are referred to as Tasks.
Remarks: Instantiated operators are referred to as Tasks.
 Remarks: With hooks, you don’t have to worry about how and where to store these connection strings and secrets in your code.
Remarks: With hooks, you don’t have to worry about how and where to store these connection strings and secrets in your code.
 Remarks: Here is the Apache Airflow documentation on context variables that can be included as kwargs.
Remarks: Here is the Apache Airflow documentation on context variables that can be included as kwargs.